

What is a RAG Pipeline?
A RAG pipeline retrieves relevant documents from a knowledge base and feeds them to an LLM at query time — so the AI answers based on your actual data, not just its training knowledge. It eliminates hallucination in domain-specific AI applications.
Here’s the problem most businesses run into within the first 90 days of deploying an AI assistant or enterprise chatbot: the model sounds intelligent, but it doesn’t know your business. It hallucinates policy details. It gives customers outdated pricing. It cannot answer questions about your internal processes because that information was never part of its training data.
That’s not a model problem. That’s a retrieval problem. And a RAG pipeline is exactly how you fix it.
Retrieval-Augmented Generation — the architecture behind the RAG pipeline — is the single most impactful upgrade you can make to an enterprise AI system in 2026. This guide explains what a RAG pipeline is, how it works, what types exist, how to build one, and how to choose the right architecture for your business. No jargon for its own sake. No academic fluff. Just the decision-making framework you actually need.
Not Sure Which RAG Architecture Is Right for Your Business? Our AI Experts Will Map It Out for You.
What Is a RAG Pipeline? The Definition That Actually Makes Sense
A RAG pipeline — short for Retrieval-Augmented Generation pipeline — is an AI architecture that connects a large language model (LLM) to an external knowledge source at the moment a query is made. Instead of relying solely on what the model learned during training, the RAG pipeline retrieves relevant documents, passages, or data in real time and feeds them to the LLM as context before generating a response.
In plain terms: a RAG pipeline gives your AI a memory it can update without retraining the model. That distinction is what makes it so powerful for enterprise applications where accuracy, recency, and domain specificity are non-negotiable.
RAG pipeline meaning goes beyond the technical definition. For business decision-makers, it means your AI can answer questions about your products, your policies, your customers, and your operations — accurately, consistently, and without the hallucination risk that makes ungrounded LLMs a liability in production environments.
How a RAG Pipeline Works: Step-by-Step Architecture
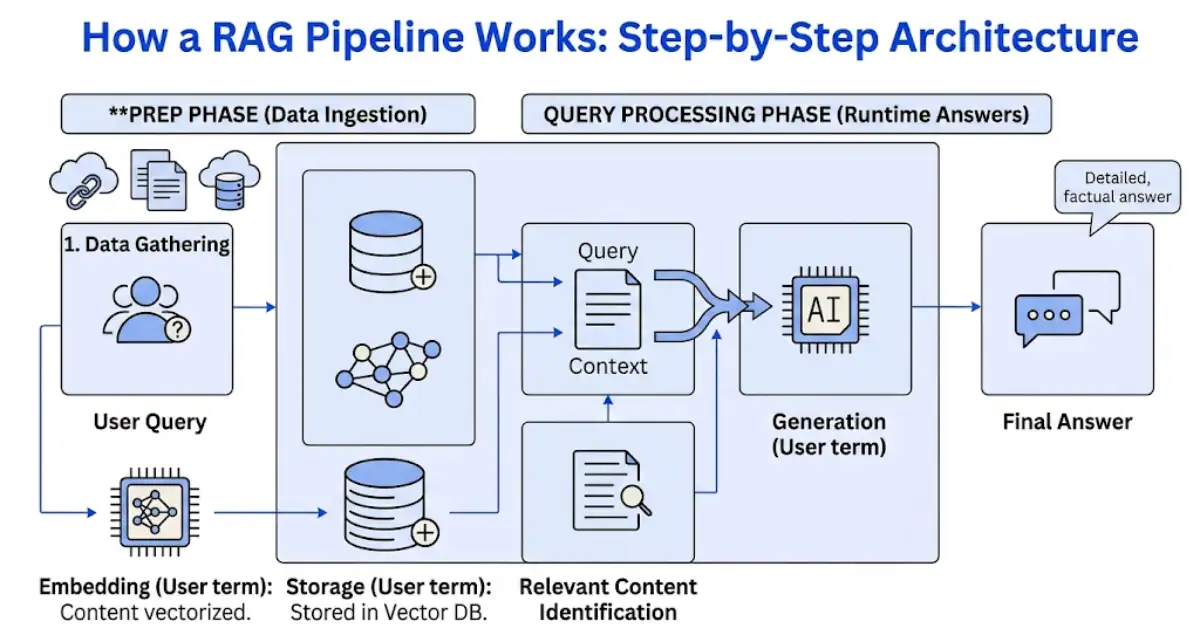
Understanding the RAG pipeline architecture helps you make better decisions about tools, infrastructure, and implementation partners. Here is how a standard RAG pipeline flows from user query to grounded AI response:
- Ingestion: Source documents — PDFs, web pages, internal databases, knowledge bases, CRM records — are processed and split into chunks.
- Embedding: Each chunk is converted into a vector embedding (a numerical representation of meaning) using an embedding model.
- Storage: Embeddings are stored in a vector database — the retrieval engine that makes semantic search possible at scale.
- Query processing: When a user submits a query, that query is also embedded and compared against stored vectors to find the most semantically relevant chunks.
- Context injection: The retrieved chunks are injected into the LLM’s prompt as context — grounding the model’s response in your actual data.
- Generation: The LLM generates a response based on both the query and the retrieved context, producing an answer that is accurate, traceable, and domain-specific.
A RAG pipeline diagram typically visualizes this as two parallel tracks — offline ingestion and online retrieval — converging at the generation step. This architecture is what separates a grounded enterprise AI system from a generic chatbot that guesses at answers.
The choice of vector DB for RAG is one of the most consequential infrastructure decisions in the pipeline. Options like Pinecone, Weaviate, Qdrant, and pgvector each carry different performance profiles for scale, latency, and cost. Getting this decision right early prevents expensive re-architecture later. For a broader view of how RAG fits into intelligent automation, see our guide on Intelligent Automation Services: ROI, Use Cases & Getting Started.
Different Types of RAG Techniques: Choosing the Right Architecture
Not all RAG pipelines are built the same way. As enterprise requirements have grown more complex, several distinct RAG techniques have emerged — each optimized for different use cases, data types, and accuracy requirements.
1. Naive RAG Pipeline
The original RAG pipeline architecture. Documents are chunked, embedded, retrieved by vector similarity, and fed to the LLM. Fast to deploy and effective for straightforward Q&A use cases over structured knowledge bases. The limitation is that retrieval quality is dependent entirely on embedding similarity — which can miss nuanced or multi-part questions.
2. Advanced RAG Pipeline
The advanced RAG pipeline addresses naive RAG’s retrieval limitations through techniques including query rewriting, hybrid search (combining vector and keyword retrieval), re-ranking retrieved results, and chunk-level metadata filtering. For enterprise deployments requiring high accuracy across diverse document types, advanced RAG is the minimum viable architecture.
3. Modular RAG Pipeline
A modular RAG pipeline decouples each component — retriever, re-ranker, reader, generator — so they can be swapped, upgraded, or A/B tested independently. This architecture is preferred by engineering teams who need flexibility and continuous improvement without full pipeline rebuilds. Frameworks like LangChain and LlamaIndex are commonly used to assemble modular RAG pipelines.
4. Agentic RAG
Agentic RAG represents the most sophisticated evolution of the RAG pipeline. In an agentic RAG system, an AI agent — rather than a fixed retrieval algorithm — decides when to retrieve, what to retrieve, from which sources, and whether to combine retrieval with tool use, web search, or multi-step reasoning.
Agentic RAG architecture enables workflows that adapt dynamically to query complexity. A simple factual question triggers a single retrieval. A multi-step analytical question triggers an agentic RAG workflow that orchestrates multiple retrievals, intermediate reasoning steps, and tool calls before generating a final answer. This is what separates static knowledge retrieval from genuinely intelligent enterprise AI.
For organizations evaluating agentic RAG systems or agentic RAG tools, the key question is whether your use case requires dynamic decision-making at query time — or whether a well-tuned advanced RAG pipeline will meet your accuracy requirements. Most enterprises begin with advanced RAG and evolve toward agentic architectures as use case complexity grows.
| RAG Type | Best For | Key Advantage | Key Limitation |
|---|---|---|---|
| Naive RAG | Simple Q&A over structured knowledge bases | Fast to deploy | Misses nuanced, multi-part questions |
| Advanced RAG | Enterprise deployments with diverse document types | High accuracy via hybrid search + re-ranking | More complex to configure |
| Modular RAG | Teams needing flexibility and continuous improvement | Swap or upgrade components independently | Requires engineering ownership |
| Agentic RAG | Complex, multi-step analytical queries | Dynamic retrieval + tool use + multi-hop reasoning | Highest implementation complexity |
RAG LLM Pipeline: How the Language Model Fits Into the Architecture
The RAG LLM pipeline is not just about retrieval — the language model you select as the generator determines the quality ceiling of every response your system produces. In a well-designed RAG pipeline, the LLM’s role is to reason over retrieved context, synthesize information from multiple sources, and generate a coherent, accurate answer in natural language.
The most important LLM selection criteria for a RAG pipeline in production:
- Context window size: Larger context windows allow more retrieved chunks to be injected simultaneously — critical for complex queries requiring broad document coverage.
- Instruction-following accuracy: The LLM must reliably use only the retrieved context and avoid hallucinating information not present in the retrieved documents.
- Latency profile: Enterprise RAG pipelines serving real users require response times that do not frustrate the end-user experience. Model size and hosting infrastructure directly affect this.
- Cost per token at scale: A RAG pipeline processing thousands of queries per day with large context injections can generate significant API costs if the LLM selection is not cost-optimized.
Whether you’re building a LangChain RAG pipeline, a LlamaIndex RAG pipeline, or a custom-built architecture, the LLM choice should be validated against your specific document corpus — not just generic benchmarks. Performance on your data is the only metric that matters in production. See how RAG as a Service handles LLM selection and pipeline tuning for enterprise deployments.
Choosing the Wrong LLM Can Break Your Entire RAG Pipeline. Let Our Experts Help You Get It Right the First Time.
How to Build a RAG Pipeline: A Practical Framework for Business Teams
Knowing how to build a RAG pipeline is the question that separates organizations who talk about AI from those who deploy it. The following framework reflects the decision sequence that production RAG pipeline builds actually follow — not the simplified tutorial version.
Phase 1: Define the Use Case and Success Metrics
Every RAG pipeline build starts with a specific problem. What questions will users ask? What documents contain the answers? What does ‘correct’ look like? Define precision and recall targets before touching any code or infrastructure. Vague success criteria produce vague RAG pipelines.
Phase 2: Data Preparation and Ingestion
The quality of your RAG pipeline is directly proportional to the quality of your ingested data. Document cleaning, formatting normalization, metadata tagging, and chunking strategy decisions all happen in this phase. Poor chunking — too large, too small, or at arbitrary boundaries — is the most common cause of retrieval failure in production RAG pipelines.
Phase 3: Embedding Model Selection
The embedding model determines how well your RAG pipeline understands semantic similarity across your specific domain. General-purpose embedding models work adequately for broad knowledge bases. Domain-specific corpora — legal, medical, financial, technical — often benefit from fine-tuned or domain-adapted embedding models that produce more accurate retrieval.
Phase 4: Vector Database Selection and Configuration
Choosing the right vector DB for RAG at this phase prevents scaling pain later. Evaluate options based on your expected document volume, query per second requirements, metadata filtering needs, and deployment environment. NVMe storage for RAG retrieval pipelines becomes relevant at very large index sizes where retrieval latency is a bottleneck.
Phase 5: Retrieval Strategy Design
A naive similarity search is rarely sufficient for enterprise RAG pipelines. Define your hybrid search strategy, implement a re-ranking layer to surface the most relevant chunks ahead of less relevant ones, and test retrieval performance against a representative set of real user queries before moving to generation testing.
Phase 6: RAG Evaluation Pipeline
Before going to production, build a RAG evaluation pipeline that measures retrieval precision, answer faithfulness, and response relevance against a ground truth dataset. Frameworks like RAGAS provide standardized RAG evaluation metrics that give you a defensible quality baseline. Never skip this phase — it is the difference between a RAG pipeline that gets deployed and one that gets quietly decommissioned after early user complaints.
For teams who need help executing this framework, our Workflow Automation Services and RAG as a Service provide end-to-end implementation support.
RAG Pipeline on Azure: Enterprise Cloud Deployment Considerations
The RAG pipeline Azure ecosystem — including Azure OpenAI Service, Azure AI Search, and Azure Blob Storage — provides a fully managed infrastructure path for enterprises that need to deploy RAG pipelines within existing Microsoft cloud agreements and compliance frameworks.
Key Azure RAG pipeline components:
- Azure AI Search: Managed vector search with hybrid retrieval (vector + BM25 keyword) built in — reducing infrastructure overhead for retrieval layer implementation.
- Azure OpenAI Service: Access to GPT-4 and embedding models within Azure’s compliance boundary — critical for regulated industries handling sensitive data.
- Azure Blob Storage: Scalable document storage with native integration into the ingestion layer of the RAG pipeline.
- Azure AI Studio: Orchestration and evaluation tooling for RAG pipeline development, testing, and monitoring in a managed environment.
For organizations with existing Azure infrastructure, a RAG pipeline Azure deployment typically reduces time-to-production significantly compared to building on open-source components — at the cost of some architectural flexibility. The right choice depends on your engineering resources, compliance requirements, and speed-to-value priorities.
Open Source RAG Pipeline: When It Makes Sense and When It Doesn’t
The open source RAG pipeline ecosystem has matured significantly. LangChain, LlamaIndex, Haystack, and DSPy each provide composable frameworks for building production-grade RAG pipelines without vendor lock-in. Pairing these frameworks with open source vector databases like Qdrant, Weaviate, or Chroma, and open source LLMs like Mistral or Llama 3, makes a fully open RAG pipeline architecture viable in 2026.
An open source RAG pipeline makes sense when:
- Your data cannot leave your infrastructure due to regulatory or contractual requirements
- You need full architectural control over every component for compliance or auditability
- Your engineering team has the capacity to own ongoing maintenance and optimization
- You are building a differentiated AI product where proprietary APIs create competitive risk
An open source RAG pipeline is the wrong choice when:
- You lack in-house ML engineering expertise to tune and maintain the pipeline
- Your time-to-production window is tight and vendor-managed infrastructure removes deployment friction
- Your document volume and query load are better served by managed scaling than self-hosted infrastructure
The build-vs-buy decision for a RAG pipeline is ultimately a resource allocation question. For organizations without a dedicated AI engineering function, partnering with a specialist — such as Exotica AI Solutions — provides access to production RAG pipeline expertise without building the internal team from scratch.
Agentic RAG: When Your RAG Pipeline Needs to Think, Not Just Retrieve
Standard RAG pipelines are excellent at answering well-defined questions against a known document corpus. But enterprise AI use cases increasingly demand something more: the ability to reason across multiple retrieval steps, use tools, query different knowledge sources depending on context, and adapt retrieval strategy based on query complexity.
This is precisely what agentic RAG delivers. In an agentic RAG architecture, an AI agent acts as the orchestration layer — deciding not just what to retrieve, but when, from where, and how to combine retrieved information with other capabilities like web search, code execution, or API calls.
Agentic retrieval enables use cases that are simply not achievable with static RAG pipelines:
- Multi-hop reasoning: Answering a question that requires retrieving information from Document A to formulate a follow-up query that retrieves from Document B — chaining retrievals intelligently.
- Dynamic source selection: Routing queries to the most appropriate knowledge source — internal documents, external APIs, or real-time web search — based on query type.
- Self-correction loops: The agent evaluates retrieved context quality and triggers additional retrieval when the initial results are insufficient to answer the query accurately.
- Tool-augmented generation: Combining retrieval with tool use — running calculations, querying databases, or executing code — to produce answers that go beyond what document retrieval alone can provide.
Companies specializing in scalable agent-RAG pipelines and agent-based RAG pipelines for enterprise search platforms are seeing strong demand from organizations that have already deployed basic RAG and are hitting the ceiling of what static retrieval can accomplish. If your current RAG pipeline is struggling with complex, multi-part queries, agentic RAG is the natural next step.
Explore agentic RAG and enterprise AI pipeline capabilities at ai.exoticaitsolutions.com. For more on how automation and AI work together at the enterprise level, see our Best Business Process Automation Tools in 2026 guide.
RAG Pipeline Use Cases: Where It Delivers Real Business ROI
A RAG pipeline is not a general-purpose AI upgrade. It is a targeted solution for specific, high-value business problems where LLM accuracy and domain grounding are critical. Here are the use cases where RAG pipelines consistently deliver measurable ROI:
- Enterprise knowledge search: Employees ask natural language questions and get accurate answers from internal documentation, policies, and procedures — replacing hours of manual document search.
- Customer support automation: AI agents grounded in your product knowledge base, FAQs, and customer history handle tier-1 support queries accurately without hallucinating policy details. See how AI chatbot solutions leverage RAG for this exact use case.
- Legal and compliance review: RAG pipelines enable AI-assisted contract review, regulatory compliance checking, and legal research grounded in your specific document corpus and jurisdiction.
- Financial analysis: Analysts query earnings reports, market data, and internal financial documents through a RAG pipeline — getting synthesized insights in seconds instead of hours.
- Healthcare documentation: Clinical AI systems use RAG pipelines to retrieve patient records, clinical guidelines, and drug interaction data at the point of care — grounding responses in verified medical knowledge.
- Software development: Developer AI assistants grounded through a RAG pipeline in your codebase, internal APIs, and technical documentation provide accurate, context-aware code suggestions and explanations.
In every use case, the RAG pipeline delivers its value through the same mechanism: connecting a powerful language model to the specific knowledge your users need, at the moment they need it. The use case determines the architecture. The architecture determines the tools. And the tools determine who builds it well. Learn more about building production RAG pipelines at exoticaitsolutions.com.
Ready to Deploy a RAG Pipeline That Actually Works in Production? See It Live in Your Environment.
Frequently Asked Questions: RAG Pipeline
The Bottom Line: A RAG Pipeline Is How Enterprise AI Gets Grounded in Reality
Generic AI answers generic questions generically. If your business requires AI that knows your products, your policies, your customers, and your operational context — and that gets those details right every time — a RAG pipeline is not optional. It is the architecture that makes enterprise AI trustworthy.
The RAG pipeline landscape in 2026 offers more options than ever: naive RAG for simple deployments, advanced RAG for production accuracy, modular RAG for engineering flexibility, and agentic RAG for use cases that require dynamic, multi-step intelligence. The organizations winning with AI are not the ones who deployed a chatbot. They are the ones who built a grounded, evaluated, production-hardened RAG pipeline on top of their own knowledge.
Whether you are building your first RAG pipeline or scaling an existing one toward agentic architecture, the path forward starts with a clear-eyed assessment of your data, your use case, and your engineering resources. Visit Exotica AI Solutions or explore the full capabilities of AI pipeline architecture at ai.exoticaitsolutions.com to explore how production RAG pipelines are built, evaluated, and scaled in real enterprise environments.
Related Reading
- RAG as a Service — Exotica AI Solutions
- AI Chatbot Services
- Workflow Automation Services
- CRM Integration Services
- Intelligent Automation Services: ROI, Use Cases & Getting Started
- Best Business Process Automation Tools in 2026
- AI in Logistics: Route Optimization, Dispatch & Customer Support
- LangChain Documentation — RAG Pipeline Frameworks
- LlamaIndex Documentation — Building RAG Applications

Mohit Thakur is an experienced Digital Marketing Expert, SEO Team Leader, and Content Writer with over 6 years of expertise in search engine optimization, content strategy, and digital growth. He specializes in research-driven SEO and crafting high-quality, compelling content that helps businesses improve their online visibility, organic traffic, and lead generation.
With hands-on experience across multiple industries, Mohit focuses on creating user-focused, well-researched content aligned with the latest Google algorithms and AI search trends. His approach combines technical SEO, content writing, content optimization, and data analysis to deliver consistent and measurable results.





